Ascend AI Processor Architecture and Programming
主要摘自《Ascend AI Processor Architecture and Programming: Principles and Applications of CANN》中基础理论方面的介绍。
Neuron model
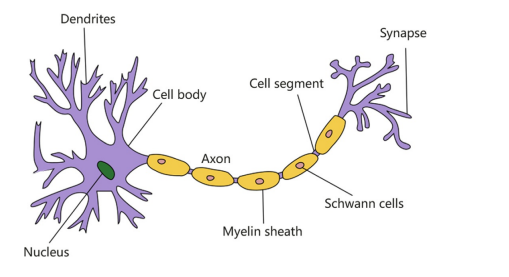
The most basic unit in a biological neural network is a neuron, and its structure is shown in the following image. In the original mechanism of biological neural networks, each neuron has multiple dendrites, one axon, and one cell body.
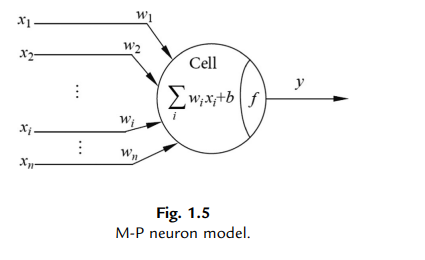
And then, it can be abstracted into a more mathematical model, called M-P neuron model
Perception
Single Perceptron
The perceptron can only deal with linear classification problems, and the output results are limited to 0 and 1.
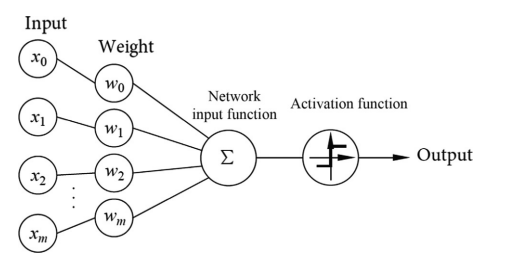
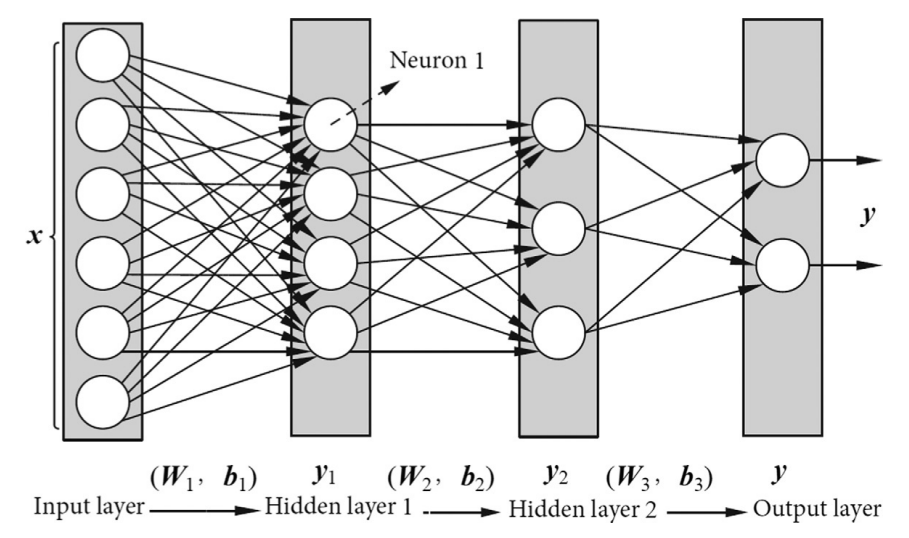
Multilayer perceptron
This deep structure is called multilayer perceptron (MLP), also known as a fully connected neural network (FCNN). An MLP can classify an input into multiple categories.
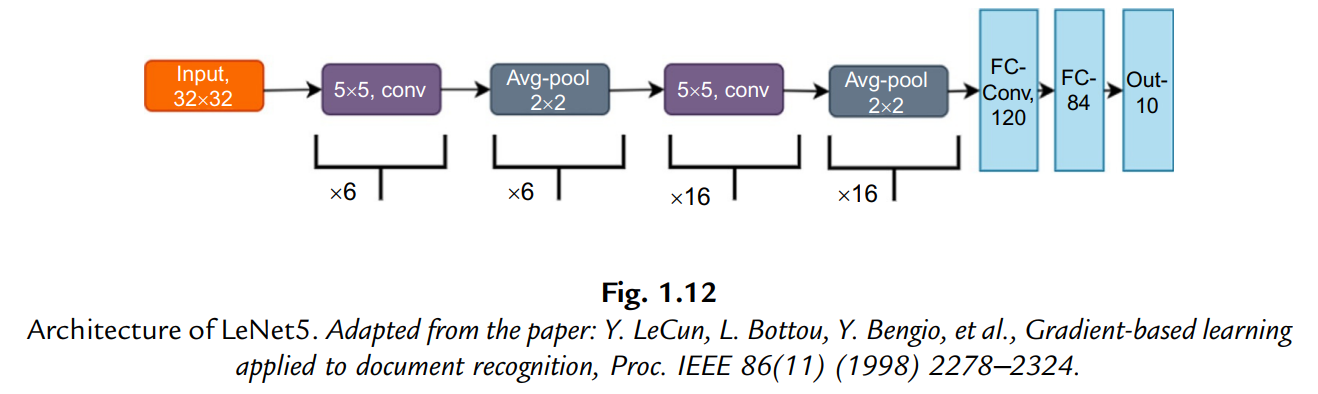
Convolutional Neural Network
CNNs require three processes: build the network architecture, train the network, and perform inference. For a specific application, a hierarchical architecture of CNNs, including an input layer, convolution layers, pooling layers, fully connected layers, and output layer, are required.
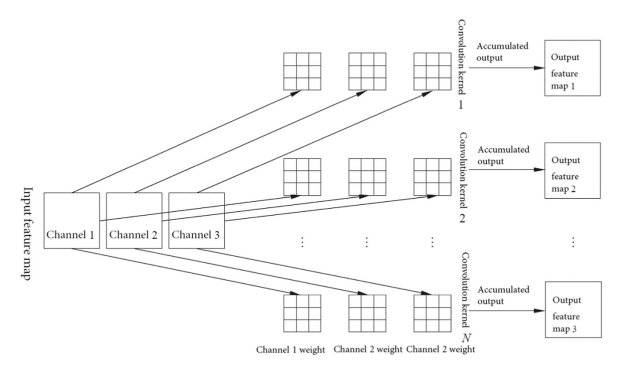
Convolution layers
The convolution kernel weights generally use a matrix of size 1x1, 3x3, or 7x7, and the weight of each convolution kernel is shared by all convolution windows on the input feature map.
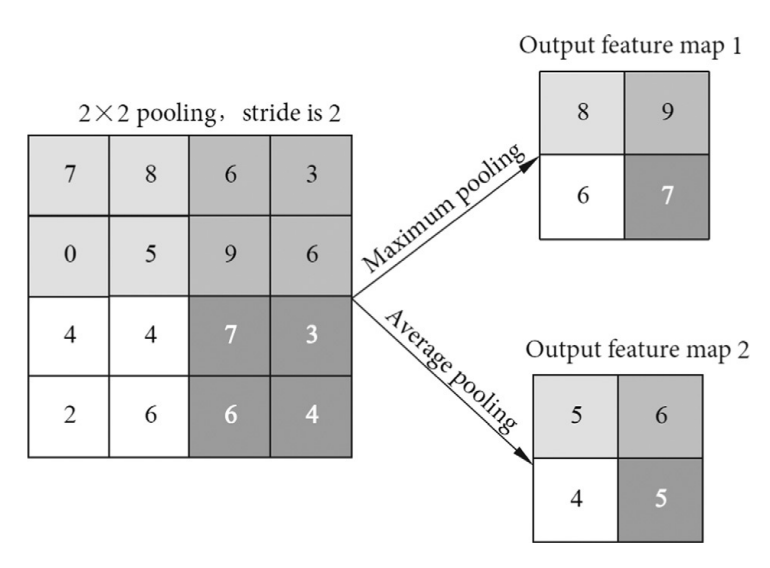
Pooling layers
- Background
- the number of neurons increases, and amouts of parameters need to be trained.
- the overfitting problem.
- The pooling layer typically uses a filter to extract representative features for diffterent locations.
Fully connected layers
A fully connected layer is equivalent to an MLP, which performs classification upon input features.
Parallelism
-
Synaptic parallelism: For convolution kernels of size
, the maximum synaptic parallelism is also . 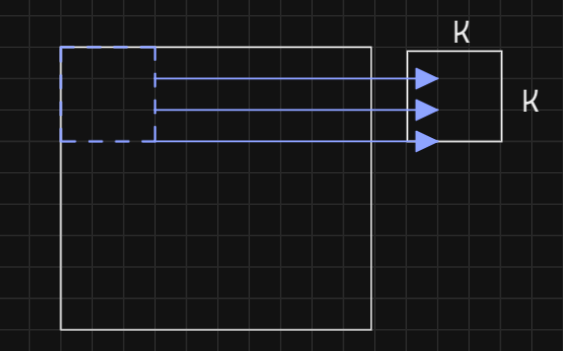
-
Neuron parallelism: Each of the convolution windows has no data dependency upon the other and thus can be computed in parallel.
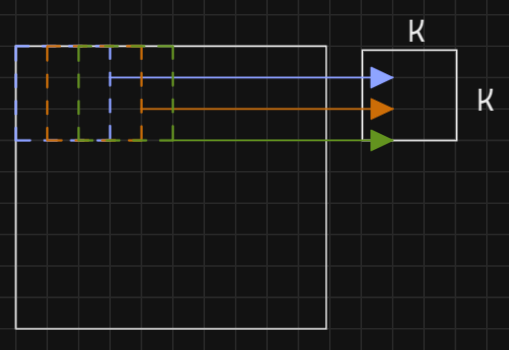
-
Input feature map parallelism: the maximum parallelism for an input image with N channels is N.
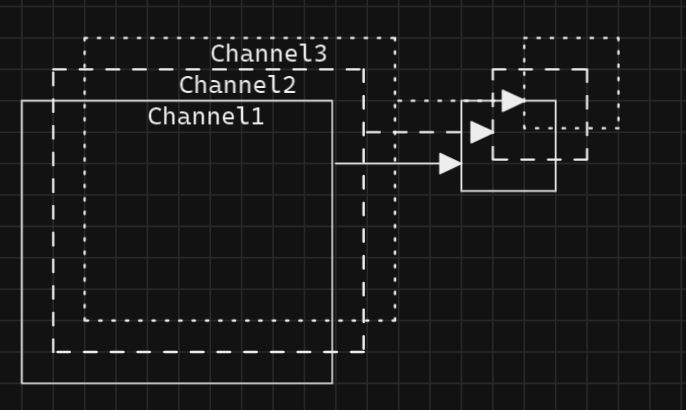
-
Output feature map parallelism: Just same as the input feature map parallelism
-
Batch parallelism: In the practical application of CNNs, in order to make full use of the bandwidth and computing power of the hardware, more than one image are processed at a time, which form a batch.
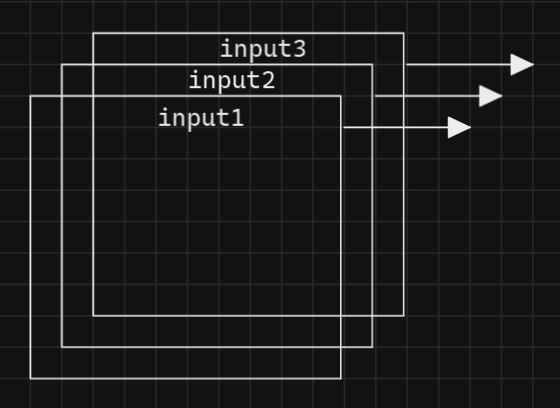
Neural network processor acceleration theory
GPU acceleration theory
The major ways to accelerate neural networks with GPUs are through parallelization and vectorization.
The vectorization approach can be illustrated by the following diagram.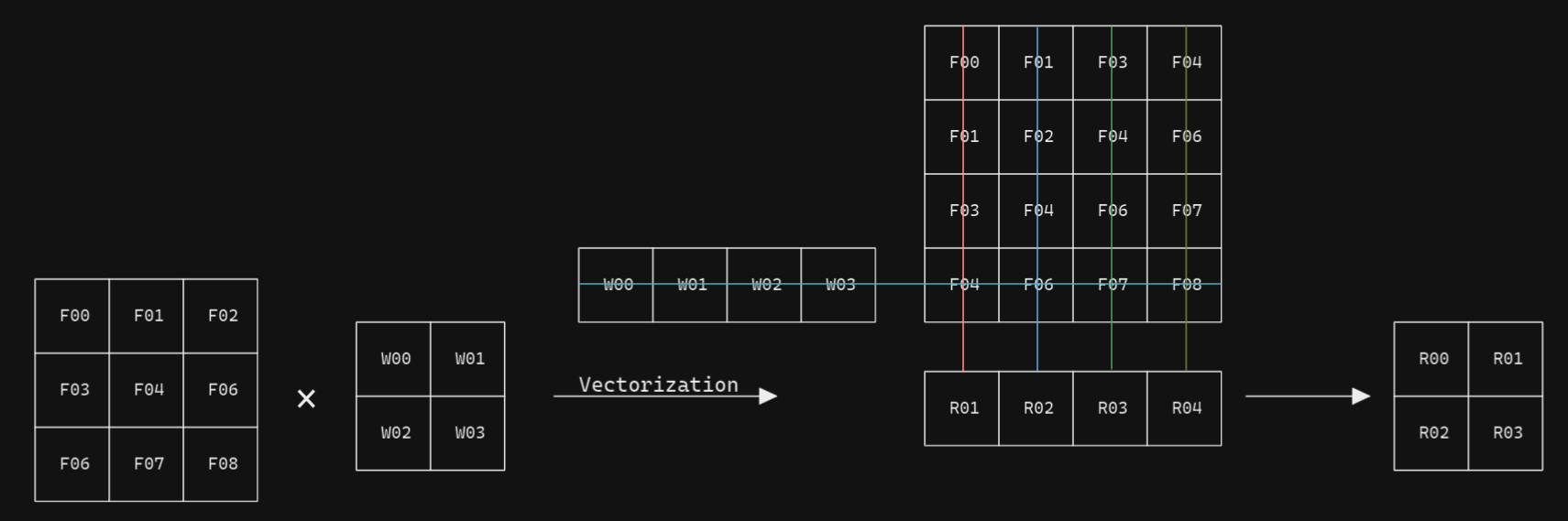
And the multiplication and addition operations can be parallezed and processed by parallel computing components.
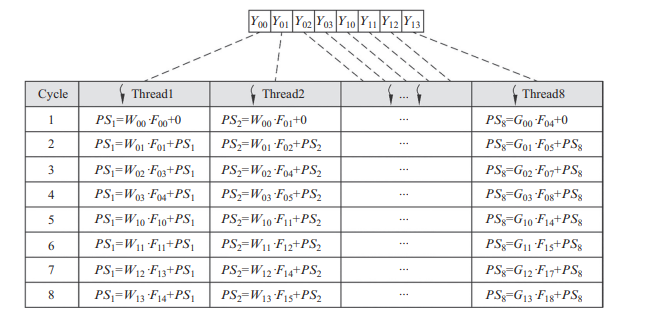
With the development of the GPU industry, more and more GPUs with modern architecure have been develeped. Like the Turing Stream Processor. The most important part of the Turing Stream Processor is Tensor Core,and each tensor core can perform 64 times of fused multiply and add (FMA) operations with the precision of FP16 in one clock cycle.
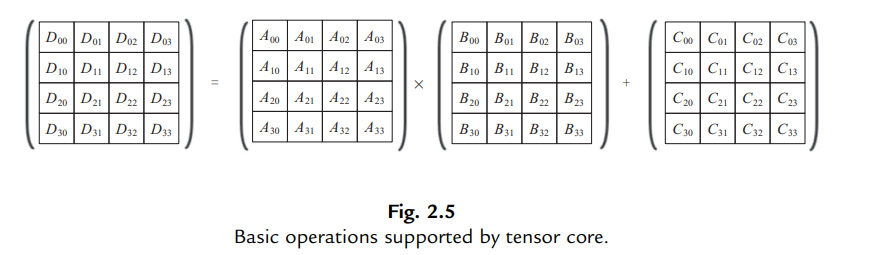
TPU acceleration theory
The way in which the convolution is computed in the TPU is different from that of the GPU, which mainly relies on a hardware circuit structure called “systolic array.” As shown in the following figure.
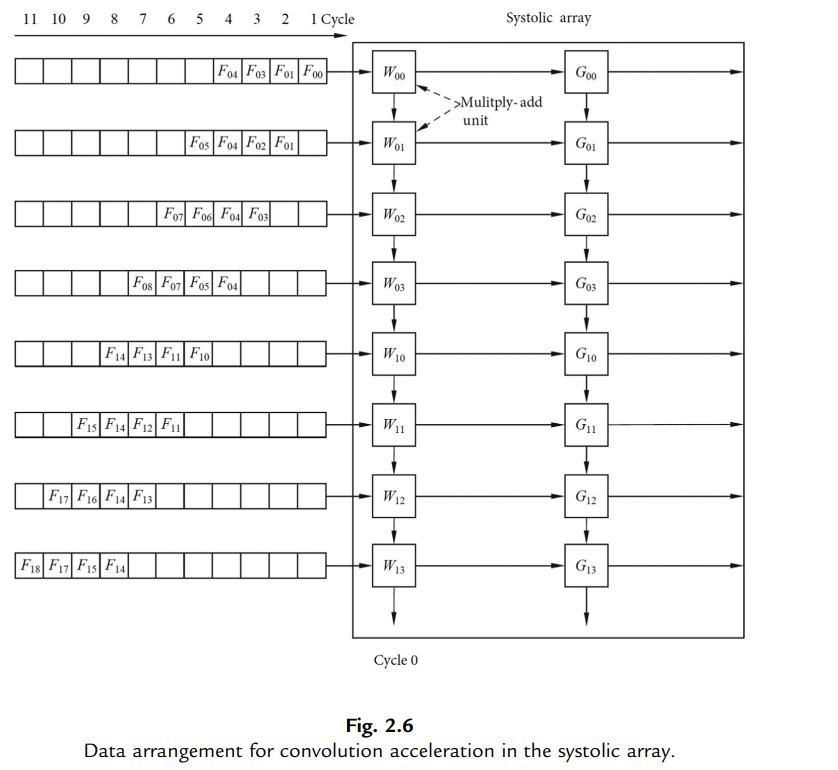
And the "systolic array" is a simple and regular but practical design.
DaVinci architecture
Unlike traditional CPUs and GPUs that support general-purpose computing, or ASIC processors dedicated to a particular algorithm, the DaVinci architecture is designed to adapt to common applications and algorithms within a particular field, commonly referred to as “domain-specific architecture (DSA)” processors.
It includes three basic computing resources: Cube Unit, Vector Unit and Scalar Unit. These three computing units correspond to three common computing modes: tensor, vector and scalar.
Cube Unit (CU) provides powerful parallel multiplication and addition computations, enabling AI Core to finish matrix computations rapidly. Through the elaborate design of customized circuits and aggressive back-end optimizations, the Cube Unit can complete the multiplication operation of two
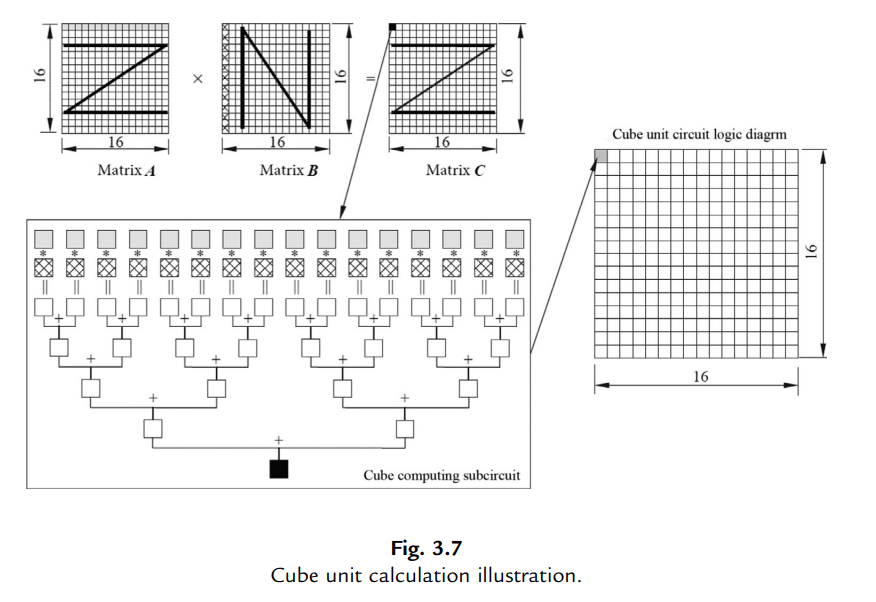
Note that the Matrix B is Column-Major.(To accelerate access efficiency)
Moreover, if the matrix is even bigger, we can use the partitioning method.
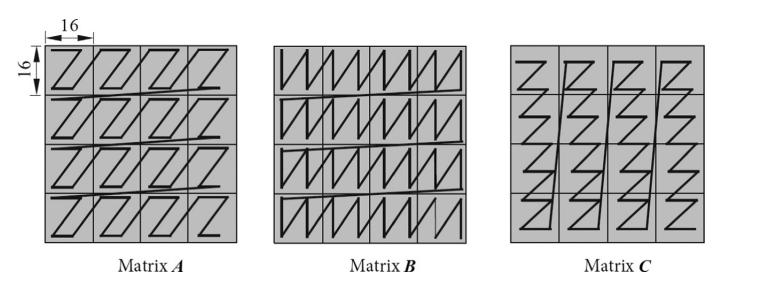
Thus, how can we apply CUBE to convolution acceleration?
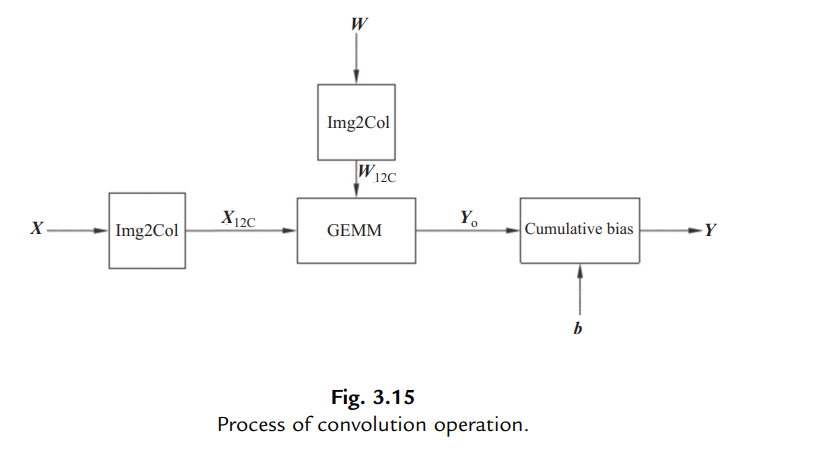
The matries will be transformed into columns(Img2Col), which can be treated as a new matrix. And then the convolution is converted to matrix multiplication.