语音信号处理与安全
背景知识
语音信号处理引用
- 语音合成(Speech synthesis)
- 语音分析(Speech analysis)
- 语音通讯和编码(Speech telecommunications and encoding)
- 语音增强(Speech enhancement)
- 语音识别(Speech recognition)
- 说话人识别(Speaker recognition)
语音信号的 A/D 转换和 D/A 转换
- A/D 转换
- 采样:每隔 T 秒取值一个连续信号 x(t)
- 量化:使用有限的比特表示
- D/A 转换
- 平滑:将数字语音转换为连续电压信号
- 插值:使用低通滤波器消除输出电压中的尖锐边缘
加窗与混叠
信号加窗:短时傅里叶变换
短时傅里叶变换的计算过程是将长时间信号分成数个较短的等长信号(加窗),然后再分别计算每段的傅里叶变换
使用不同的窗宽度会产生不同的结果:
- 太长 的窗口会导致时间分辨率下降,看不到 频谱特征在窗口的 持续时间内 的变化
- 在实践中,一般长度为 20-30ms 的语音段通常被认为是“准稳态”(频谱特征变化小),这是因为一般的语音,语音单位(音素)的发生率为每秒 4-5 个。
- 为确保能量分布从一帧到另一帧的平稳过渡,窗口一般选择为重叠的,典型的 帧移为 5ms
- 分辨率(其中,fs 是采样频率,N 是窗的大小)
- 频率分辨率 fs/N
- 时间分辨率 N/fs
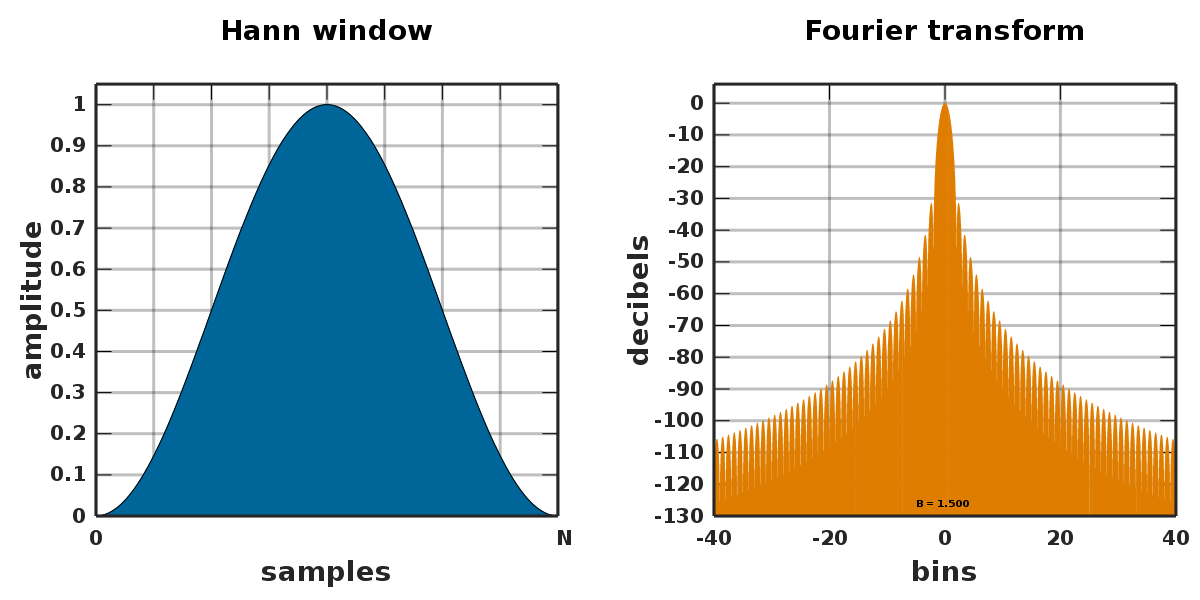
混叠的问题:频谱泄露
- 现象:一般窗内的语音是平稳的,但是在边界处可能会出现波形的尖锐不连续,不连续的结果是高频噪声出现在频谱上,这被称为 频谱泄露。
- 原理:截取信号时,需要加窗函数,即时域相乘;在频域的角度就是频域卷积,于是频谱中除了本来该有的主瓣之外,还会出现本没有的 旁瓣
- 解决方法 - Hann 函数:一个在两端接近零的窗口函数
互相关与自相关
- 互相关
- 定义:两个离散序列之间的相关函数
- 相关函数是对两个函数或序列之间相似性的统计测量
- 自相关
- 定义:一个序列与自身的延迟版本的相关关系
- 自相关是一种常用的技术,用于语音分析、编码和增强中的周期性估计或基本频率(音调)追踪/估计
随机信号的自相关
随机信号因为是随机的,所以与任何的延迟版本几乎都不存在相关关系,可由下图表示: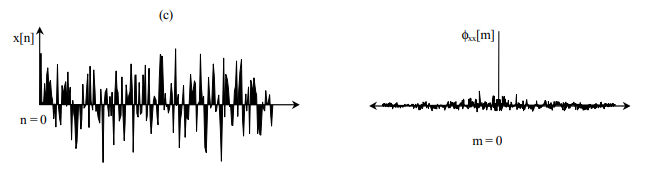
,其中 为功率谱密度
声源滤波器模型
源滤波器模型(source filter)
- 认为语音是激励的频率响应与声道的频率响应的乘法,也可以被认为是时域的卷积
,其中 是语音信号, 是激励信号, 是声道传递函数 - 声源(Source):定义语音精细结构的 激励信号。
- 噪声激励:产生非浊音的语音信号
- 周期性激励:产生浊音信号
- 声道(Vocal tract):一个可变的谐振器
- 声带振动除了产生 基频,还会产生 倍频。
- 有些频率的声音得到了加强,被称为 共振峰
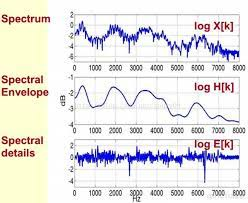
- 频谱包络:关于声调结构的信息
- 频谱细节
LPC 模型
LPC 全称为线性预测编码(Linear Prediction Coding),是语音处理和编码中用于模拟语音样本之间 短期相关性 的一种强大方法。
LPC 仍存在一些缺陷:
- LPC 的频谱包络线对频谱谷的拟合效果不佳
- 用于估计预测系数的每一帧内可能存在多个发生脉冲则不适用,比如女性或高音调语音
倒频谱分析
倒谱去卷积法(cepstral deconvolution)是一个更准确但效率较低的方法。
MFCC
- 预加重:提高高频能量
- 分帧:对音频进行分段处理
- 加窗:加汉明窗,减少频谱泄露,使得分帧音频在叠加时还原度更高
- FFT:时域转频域
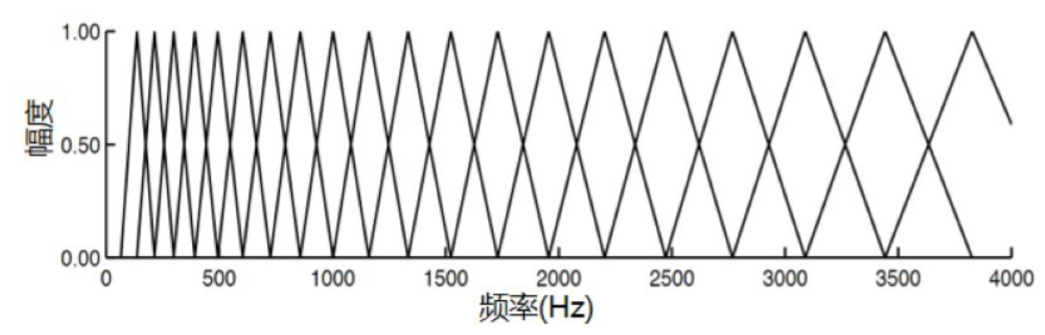
- Mel 滤波器组:一组 22-24 个非线性分布的三角带通滤波器,其在梅尔频率上均匀分布,代表 人耳对频率的感受度。
- 对数运算:
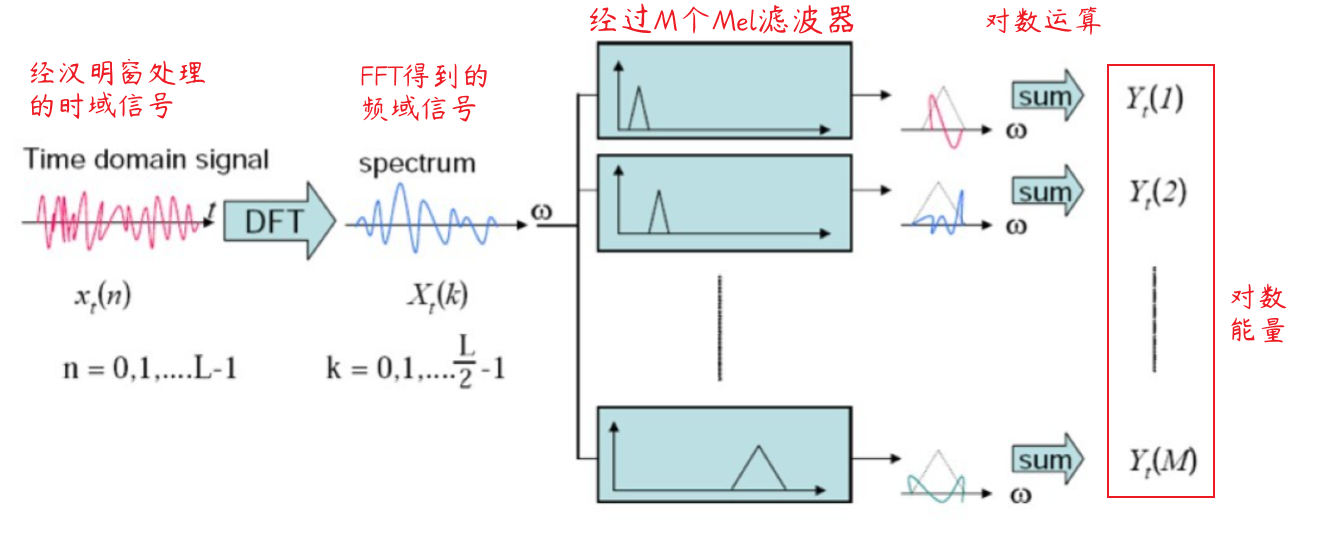
- 离散余弦变换:对滤波器组系数去相关处理,产生其压缩表示,获得 L 阶的梅尔倒谱参数。
语音识别攻击
隐蔽性语音攻击
- 特性
- 恶意语音信号 -> 触发非法操作
- 具有隐蔽性,不易察觉
- 攻击信号生成方法(从原信号出发)
- 时域逆向
- 相位偏移
- 叠加高频
- 时域尺度变换
- 具体方法
- 攻击者选择待生成攻击信号的参数:语速(时域尺度变换)、高频信号强度(叠加高频)和 窗口大小(时域逆向和随机相位)
- 攻击者将这些参数与原始音频输入至攻击信号生成模块。该模块会依据 4 种变换方式,将原始语音转换成“噪声”
- “噪声”输入至语音识别系统,该系统不会接收所有的攻击音频样本,因为有些可能被扭曲得不可识别
心理声学 Psychoacoustics
- 当有多个声源存在时人类很容易将注意力集中在单个声源上(鸡尾酒会效应)
- 人类的听觉在 添加背景噪音 的情况下也可 感知到语音
- 与低频相比,人们 对高频的差异辨别能力很差
- 人类也 不善于感知不连续或随机的声音