Transaction
Basic concepts
ACID
- 原子性 (Atomicity): 事务中的所有步骤只能 commit 或者 rollback。
- 一致性 (Consistency): 单独执行事务可以保持数据库的一致性。
- 隔离性 (Isolation): 事务在并行执行的时候不能感知到其他事务正在执行,中间结果对于其他执行的事务是隐藏的。
- 持续性 (Durability): 更新之后哪怕软件出了问题,更新的数据也必须存在。
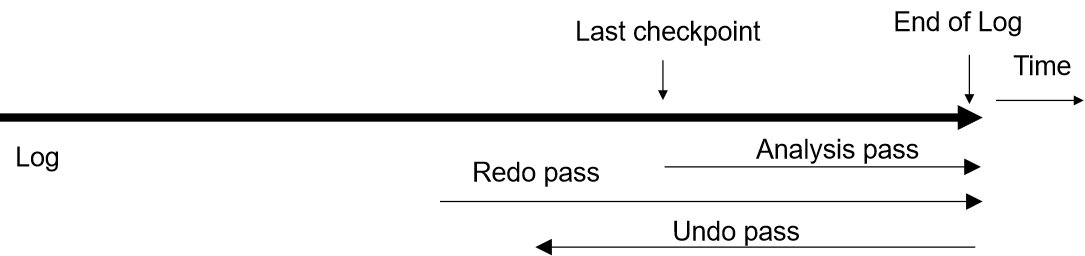
状态
- active:初始状态,执行中的事务都处于这个状态。
- partially committed:在最后一句指令被执行之后。
- failed:在发现执行失败之后。
- aborted:回滚结束,会选择是重新执行事务还是结束。
- committed:事务被完整的执行
Concurrent Executions
- serial schedule 串行调度:一个事务调度完成之后再进行下一个
- equivalent schedule 等价调度:改变处理的顺序但是和原来等价
- conflict serializability 冲突可串行化
- conflict equivalent:两个调度之间可以通过改变一些不冲突的指令来转换,就叫做冲突等价
- conflict serializable:冲突可串行化:当且仅当一个调度 S 可以和一个串行调度等价
- Precedence graph 前驱图
- Recoverable Schedules 可恢复调度
- 如果一个事务
要读取某一部分数据,而 要写入同一部分的数据,则 必须在 commit 之前就 commit,否则就会造成 dirty read
- 如果一个事务
- Cascading Rollbacks 级联回滚: 单个事务的 fail 造成了一系列的事务回滚
- Cascadeless Schedules 避免级联回滚的调度
- Cascadeless Schedules 也是可恢复的调度
Concurrency Control
- Lock-Based Protocols
- exclusive(X) lock: 可读可写
- shared(S) lock: 可读不可写
- Lock-compatibility matrix
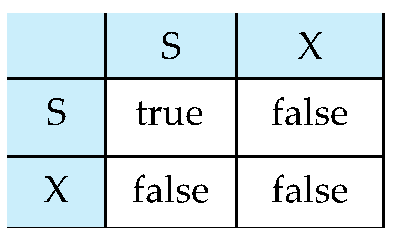
- Two-Phase Locking Protocol
- Phase 1: Growing Phase
- transaction may obtain locks
- transaction may not release locks
- Phase 2: Shrinking Phase
- transaction may release locks
- transaction may not obtain locks
- Two-Phase Locking Protocol assures serializability.
- 两个变种
- 严格两阶段封锁协议 (strict two-phase locking protocol):要求事务持有的 X 锁必须在 事务提交之后方可释放。解决级联回滚的问题。
- 强两阶段封锁协议 (rigorous two-phase locking protocol):要求事务提交前不得释放 任何锁。
- Phase 1: Growing Phase
- 锁转换 (Lock Conversions):提供了一种将 S 锁升级为 X 锁,X 锁降级为 S 锁的机制。只能在增 长阶段升级,缩减阶段降级。
- DeadLock
- 互相持有锁的时候触发死锁
- 可以通过执行事务前就要求拿到锁以避免运行时死锁(当然这样做就会有相应的性能代价)
- 通过画依赖图判断是否产生死锁
- 死锁恢复:选取一些事务进行回滚。当重复选取同样的事务牺牲 (victim) 并不断陷入死锁时,即陷入 starvation(饥饿)
Recovery System
log-based Recovery 基于日志的恢复
- 日志 (log) 被存储在稳定的存储中,包含一系列的日志记录
- 事务开始
<T start> - 写操作之前之前的日志记录
<Ti, x, V1, V2>- (X) 是写的位置,
- V1,V2 分别是写之前和之后的 X 处的值
- 事务结束的时候写入
<T commit>
- 事务开始
- 对于更新事务的两条规则
- commit rule:新的数据在 commit 之前必须被写在 非易失性 的存储器中
- logging rule:旧的值在新的写入之前需要被写在日志里
Aries 算法
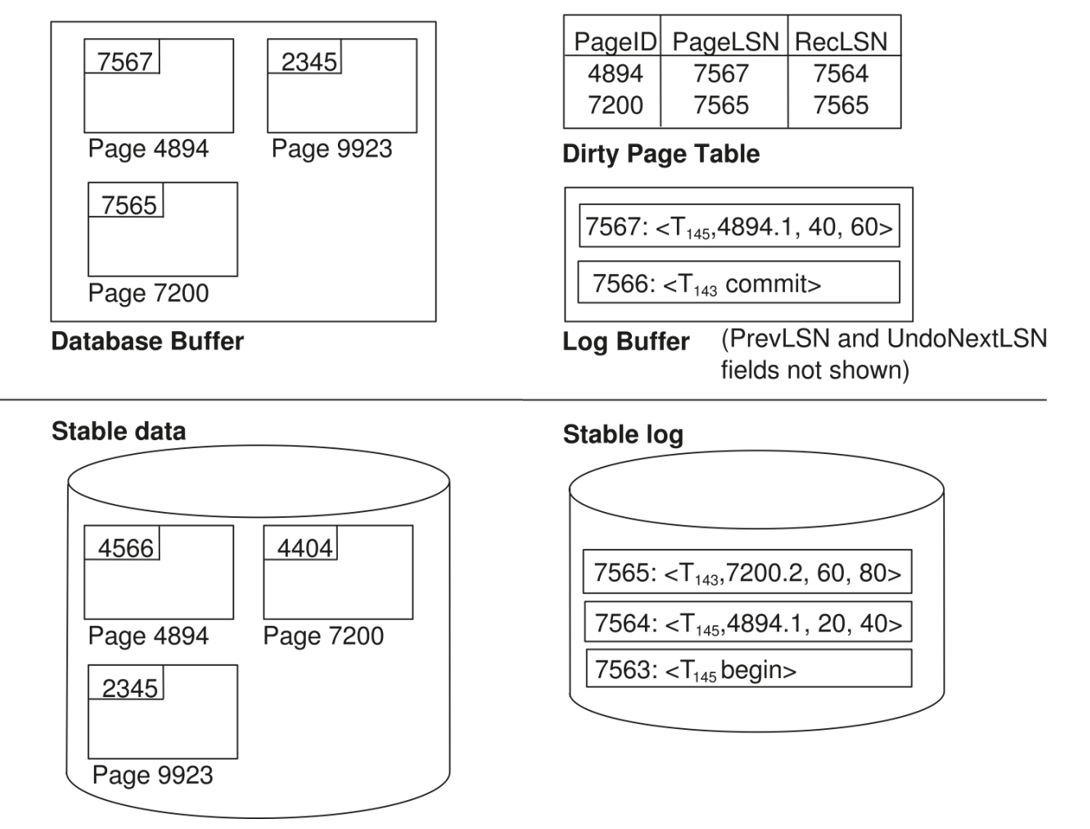
-
Log
- 记录一些必要信息
- 记录一些必要信息
-
Page LSN
- 每一页的 LSN
- 是每一页中最后一条起作用的日志记录的 LSN 编号
-
Log Buffer
- 记录的缓冲区,还没有写入 Stable log
-
Dirty Page Table
- 存储在缓冲区的,记录已经被更新过的 page 的表
- 每个页的 RecLSN,表示这一页的日志记录中,在 RecLSN 之前的 Log 已经都被写入 Stable log
-
Checkpoint
- 记录脏页表信息和活跃事务的 LastLSN
- 和 log-based Recovery 不同的是,它不会把内存页写入磁盘
-
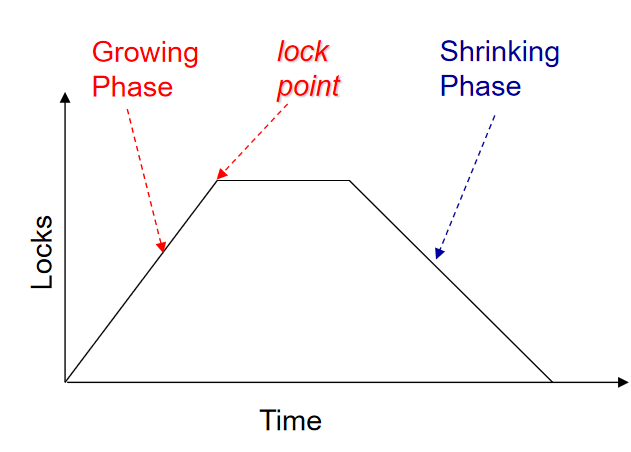
恢复操作
- 分析阶段
- 读取最后一条完整的 checkpoint 日志记录信息
- 设置 RedoLSN = min RecLSN(脏页表中的),如果脏页表是空的就设置为 checkpoint 的 LSN(决定从哪里开始 redo)
- 设置 undo-list:checkpoint 中记录的事务
- 读取 undo-list 中每一个事务的最后一条记录的 LSN
- 从 checkpoint 开始正向扫描
- 如果发现了不在 undo-list 中的记录就写入 undo-list
- 当发现一条更新记录的时候,如果这一页不在脏页表中,用该记录的 LSN 作为 RecLSN 写入脏页表中
- 如果发现了标志事务结束的日志记录 (commit, abort) 就从 undo-list 中移除这个事务
- 读取最后一条完整的 checkpoint 日志记录信息
- Redo 阶段
- 从 RedoLSN 开始正向扫描,当发现更新记录的时候如果这一页不在脏页表中。或者这一条记录的 LSN 小于页面的 RecLSN 就忽略这一条
- 否则从磁盘中读取这一页,如果磁盘中得到的这一页的 PageLSN 比这一条要小,就 redo,否则就忽略这一条记录
- Undo 阶段
- 从日志末尾先前向前搜索,undo 所有 undo-list 中有的事务
- 用分析阶段的最后一个 LSN 来找到每个日志最后的记录
- 每次选择一个最大的 LSN 对应的事务 undo
- 在 undo 一条记录之后
- 对于普通的记录,将 NextLSN 设置为 PrevLSN
- 对于 CLR 记录,将 NextLSN 设置为 UndoNextLSN
- 如何 undo:当一条记录 undo 的时候
- 生成一个包含执行操作的 CLR
- 设置 CLR 的 UndoNextLSN 为更新记录的 LSN
- 分析阶段